
资讯


从0到1构建推荐系统
日期:07-16▼
易奇科技导读:伴随着移动互联网的快速发展与信息量的飞速增长,如今用户可能每天都需要接收海量 别的信息。而推荐系统的产生让用户在一定程度上可以更精准地接收自己所需信息。那么,如何搭建好一个推荐系统?易奇小编总结了从0到1搭建推荐系统的一套方法,大家一起来看一下吧。

一、前言
本文主要是笔者在负责实际项目中积累的关于推荐系统的皮毛认知和理解。
原先都是以用户的身份接触推荐系统,所以在以PM的身份接到任务时自然是一头雾水。各种问题浮现在脑海:推荐系统是什么?能解决什么问题?如何构建?等等。
说实话,这些问题每一个都困扰了我许久。光是思考第一个问题就花了一个多月,回过头来看,整个项目周期中,大概70%的时间用于思考“是什么”的问题,剩下30%的时间是解决“怎么做”的问题(实际上整个项目中的应用系统除了推荐系统还有用户画像系统)。
当然 终的结果是乐观的。所以有意写下此文,一来是记录心得,二来是给有需要的朋友做实战分享,三来就是抛砖引玉,促进共同交流。因笔者在该行业中经验积累较为浅薄,疑虑和不妥之处还望赐教和指正。
二、推荐系统简述
1. 推荐系统是什么
从应用层面简而言之,推荐系统的主要功能是基于已知的用户数据通过算法计算并给出用户可能感兴趣的信息/物品。
2. 推荐系统诞生背景简述
随着知识的运用积累、科学技术的进步等,人类在近几百年来通过几次工业革命使得社会的生产力水平得到大幅提升。此外,从第二次世界大战结束后,人类社会加速迈入全面和平时代,全球各 的主基调以经济发展为核心主题,因而进一步加速了社会经济发展水平。
在此基础上,我们从一个生产力水平相对低下、生活物品匮乏的年代逐渐向物质水平充足、信息爆炸再过渡到当下的商品过剩、信息过载的年代。可以预见的是在未来人们在同一决策下将面临越来越多的选择。
在此背景下,消费者(用户)在面临大量的信息或者物品时可能无法真正从中获得自己期望或有用的信息或商品。与此同时,生产者的困扰在于如何让自己的信息/商品呈现给更多用户,如何在海量的信息/商品中脱颖而出。
而推荐系统正是解决这一矛盾重要工具。尤其是在平台经济模式下,推荐系统的应用 为广泛,其中较为典型并具有良好的发展和应用前景的领域包括电子商务领域、电影/视频、音乐、阅读等。
本文主要以项目中涉及的领域【电影/视频】领域为出发点进行展开。
三、从0到1构建推荐系统
1. 推荐系统的核心功能
推荐系统的核心功能就是为用户推荐其可能感兴趣的商品。大致的过程可以简述为:推荐系统依据已知的用户数据,经过推荐引擎(推荐算法)计算,并给出用户可能感兴趣的商品集合, 终再通过前端界面的方式将特定的商品呈现在用户眼前。
比如:已知用户的观影数据,此时可通过推荐算法得知用户是一名喜剧电影爱好者,于是便可以向用户推荐喜剧电影题材的视频内容。
此外,这里需要重点说明的是,如何判断用户是否感兴趣的主要依据来源于已知的用户数据。本质上是基于数据统计推断。所以这里描述的是可能感兴趣。这一点很重要。而说到用户数据,这里需要提一下方便后续的理解和扩展,用户数据的主要类型:
用户基本属性:这里主要是用户地理信息,用户社会属性数据(性别、年龄等)等。
用户行为数据:这里主要是用户的观影数据(点击、播放、收藏、订购)等。当然,考虑到人类行为动力学特征研究结果(大多数情况下,人对一件事情的关注只能持续较短的时间),在此还需要做拆分,即历史行为数据和实时行为数据。比较典型的实时推荐:某宝购物在线输入关键字搜索后退出,此时再次进入app则可能会看到与搜索关键字相关的物品。
下图为推荐系统基本功能和简要的过程:
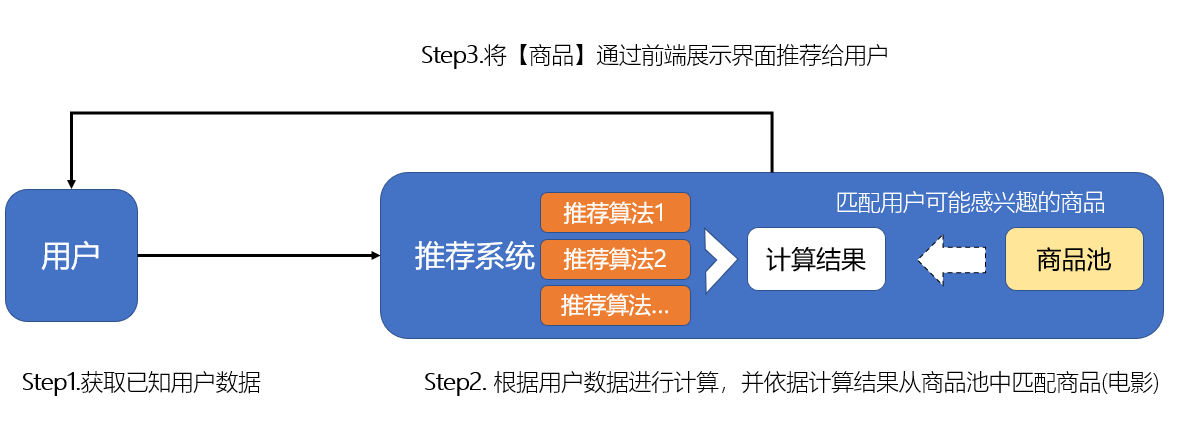
2. 推荐系统的构建
说到这里,我们似乎发现了,其实推荐系统说简单一点就是:给用户推荐商品。
如果拓展一下:那就是给什么样的用户推荐什么样的商品。再拓展一下:给什么样的(具有某种特征的用户)用户用什么样的方式(不同场景下的推荐算法)推荐什么样的(与用户特征相匹配的商品)商品。
这样理解的话,我们似乎知道可以从哪里下手了。
1)用户特征与商品特征定义
① 用户和商品的关联关系
我们需要定义一套规则把用户和商品关联起来。这样可以使得用户和商品存在某种关联关系以便达到对某特征的用户推荐关联特征的商品。
可以说用户特征和商品特征之间的关联是相辅相依的。比如:为喜剧电影偏好者推荐喜剧电影。
那么问题来了,用户和商品之间本身不存在关联关系,可以说都是相对独立的,何来关系之有?何谈建立关联关系?
这里的答案是用户的行为,用户行为使得用户和商品之间产生关联。因为一次交互,所以产生了联系。于是便有了关联关系。那么这个“交互”其实就是方才提到的: 点击、播放、收藏、订购等。用户播放了喜剧电影,则意味着用户与该喜剧电影产生了关联关系。
于是乎,我们似乎可以下一个初步的结论,用户可能对喜剧电影感兴趣。进而我们是否可以考虑为该用户推荐喜剧电影呢?有点欠妥,因为仅凭一次观影,数据量不足。
但是如果我们根据用户的大量历史行为数据发现该用户看的电影中喜剧偏多,而此刻我们认为用户对喜剧电影有偏好的结论似乎就可以站得住脚了。进而,我们可以试着给用户推荐喜剧电影了。
② 商品特征和用户特征
商品特征源自于对商品不同维度的描述。这里用商品属性代替。下表中的第一列就是商品属性(业界通常把电影电视剧等统称为媒资,因而后文中牵涉到商品的内容将以媒资来描述)。
商品属性及其属性值。这个比较好理解。下图中的【媒资题材】其实就是属性的一种,对应的属性值有:喜剧、悬疑、动作等等。
而我们可以通过商品具备的属性来建立属于商品固有的特征。商品属性越多,商品特征越丰富。如:一部喜剧电影和一部成龙主演的喜剧电影。很显然是后者的特征更丰富。所以我们明确一点:属性是构成特征的基本要素。
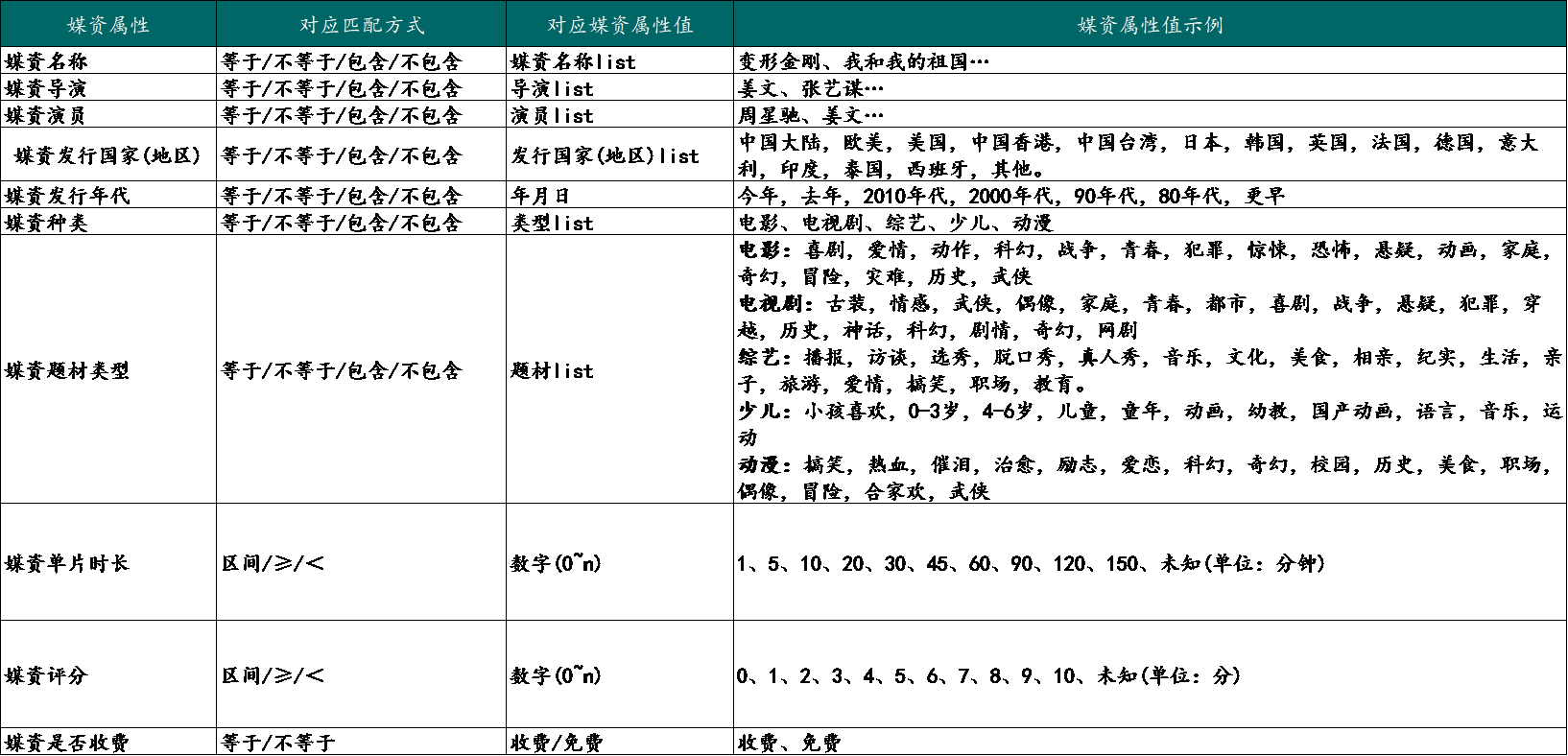
同理,对于用户特征亦是如此。通过用户属性来建立用户固有的特征(通常用用户标签来描述)。下表中是用户特征的简要示例。

在说完商品特征/用户特征以及二者之间的关系后,我们可以发现。用户通过主动行为,与商品发生关联关系,从而建立了用户与商品之间的联系,因而这就为我们做商品推荐奠定了基础。
2)推荐场景及算法逻辑构建
① 推荐场景和推荐算法的联系
通过上述过程,我们建立了用户和商品之间的联系,剩下的工作就是需要一套自动化的程序将二者的关系打通。这个自动化程序即我们要说的推荐算法。
方才有提到,推荐的本质上是基于数据统计推断。而数据我们在这里主要分为两种:
基于用户基本属性数据;
基于用户行为数据(包含历史行为数据和实时行为数据)。
我们先做个小结:这里所有的推荐算法都是基于上述两种数据完成的。
与此同时,我们不妨再回顾一下:给什么样的(具有某种特征的用户)用户用什么样的方式(不同场景下的推荐算法)推荐什么样的(与用户特征相匹配的商品)商品。
这里需要有一个问题值得思考,为什么推荐算法还需要区分场景。
这其实主要源自于应用端需求。比如,我打开了某宝, 页中可能出现了我搜索过的商品种类推荐,而在我下单后可能系统又为我推荐了其他的商品。
这里提到的“ 页状态”和“下单后”两种分别属于不同的场景。前者是我刚进app,系统可能通过我过去的行为数据发现我可能对搜索过的商品比较感兴趣,所以为我推荐相关商品,而后者是系统通过全网用户数据发现购买了当前商品A的用户同时也购买了另一款产品B,而此时我购买了该商品于是认为我可能也会下单商品B,所以为我推荐了商品B。
不同的场景下,需要有对应合适的推荐方式。于是我们将推荐场景和推荐算法联系到了一起。
我们简单地整理出示意表格中的实例:基于不同场景下对用户数据采用特定的推荐算法进行计算。

至此,我们还需要完成一项工作才能构成一个简单的推荐系统:推荐算法的逻辑。
② 推荐算法的逻辑构建
在上述的示例中,我们列举了部分推荐算法,下面一一说明:
用户偏好推荐
简而言之,依据用户历史的行为数据推荐他平常喜欢看的内容。
还是拿前面说过的:为喜剧电影偏好者推荐喜剧电影。所以我们可以制定量化规则。
如:我们统计了该用户过去的观影数据,其中观看【喜剧片】10次,【悬疑片】5次,【战争片】4次,【爱情片】1次,那么加起来合计观影次数=10+5+4+1=20次,其中按照比例计算分别占比:50%、25%、20%、5%。
那么我们通过现有的数据可以观察到,该用户的仅有数据中显示其对【喜剧片】和【悬疑片】较为有兴趣(这里我们定义从历史数据中取Top2,【喜剧】和【悬疑】符合我们自定规则),于是当用户下次开机时,我们有了在 页为用户推荐一定数量的【喜剧片】和【悬疑片】的依据。上述,大概是简单的用户偏好推荐算法。
协同过滤推荐
这里我就不献丑了。这种推荐算法比较经典,也是业界常用的推荐算法。比较典型的案例是:啤酒和尿布。超市人员发现购买啤酒的用户同时也购买了尿布。于是这个故事可以写成:买尿布的家庭中有婴儿,母亲照顾婴儿,父亲去超市买尿布同时也买啤酒。
明星偏好推荐
这里同上述第一项相似,就不再赘述了。主要目的有两个,一个是筛选出近期比较热的明星,推荐他的内容;另一部分是按照用户对明星的偏好,推荐用户偏好的明星的内容。
通过上述的推荐算法的规则的建立,结合已知的数据,我们似乎可以为单个用户做个性化推荐了。下图所示,但这里只是整个系统的一部分。

3)推荐结果的过滤和排序
完成了前面的内容后,理论上我们可以做出一个较为简单的推荐系统。但是在实际业务中还会牵涉到两项比较重要的工作需要完成:过滤和排序。
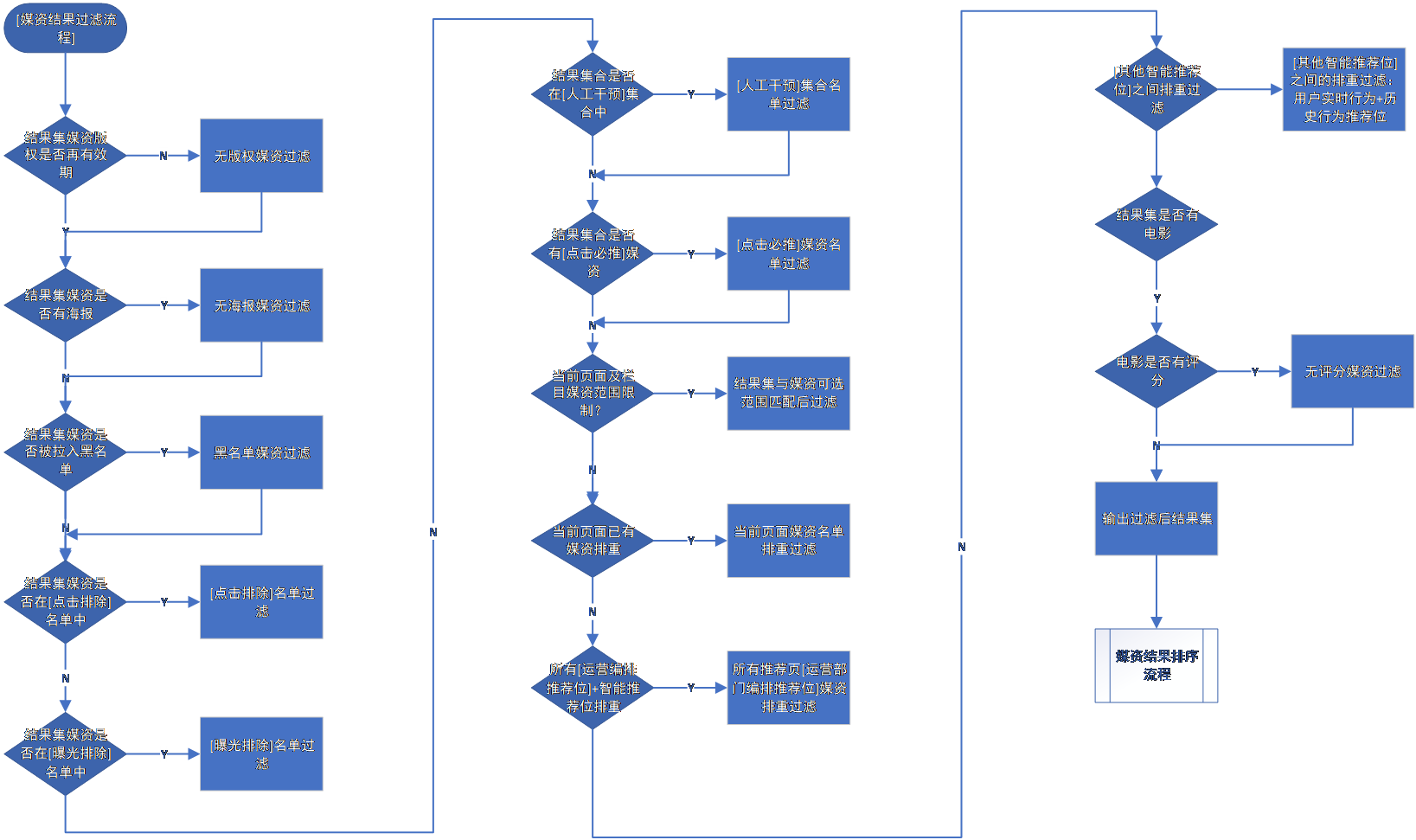
① 推荐结果的过滤
这里的过滤:主要是针对媒资库中剔除不符合业务规则的媒资的过程。而不符合业务规则需要依据实际的业务来确定,常见的不符合规则的类型有如下:
被加入黑名单的媒资内容:加入黑名单后将不再呈现在用户视野中,故而需要过滤掉。
媒资版权过期:媒资库中过滤掉版权过期的内容。
话题敏感的媒资内容:某些时间段或特殊事件引发的敏感内容“下架”。
排重过滤:这里的排重过滤也有多种形式,常见的是:推荐系统在 近的一段时间段为用户推荐过某电影,但是用户并没有播放,可能是用户对该项推荐不感兴趣。当推荐次数积累到一定程度时,系统将自动过滤该媒资。
其他:这里的过滤条件可能会有多种,主要源自于业务需求,故而不再一一列举。下面的流程图中是实际业务中需要进行过滤的选项。
② 推荐结果的排序
通过上述过滤,推荐结果的媒资集合已经被清理了一轮。但集合中剩余的内容并不是所有的媒资都需要呈现给用户。用户的视野是有限的,推荐位的数量也是有限的,所以我们应该从这个集合中再次筛选出比较“易产生兴趣”的内容,进而提升用户可能对推荐内容产生的兴趣。
排序的方式有多种,这里只列举了一部分并且是单一的排序方式。也可以通过算法规则进行综合排序等,这里只讨论单一排序。排序方式包括:
热度排序:媒资集合中所有的媒资按照热度来排序;
评分排序:按照评分大小来排序;
上线时间排序:按照上线的时间远近来排序;
其他。

4)推荐结果的展示
推荐结果的展示
在经过媒资的过滤和排序后,推荐内容已经准备好进入用户的视野了。我们重新整理并对先前的示意图做一下优化,如下:
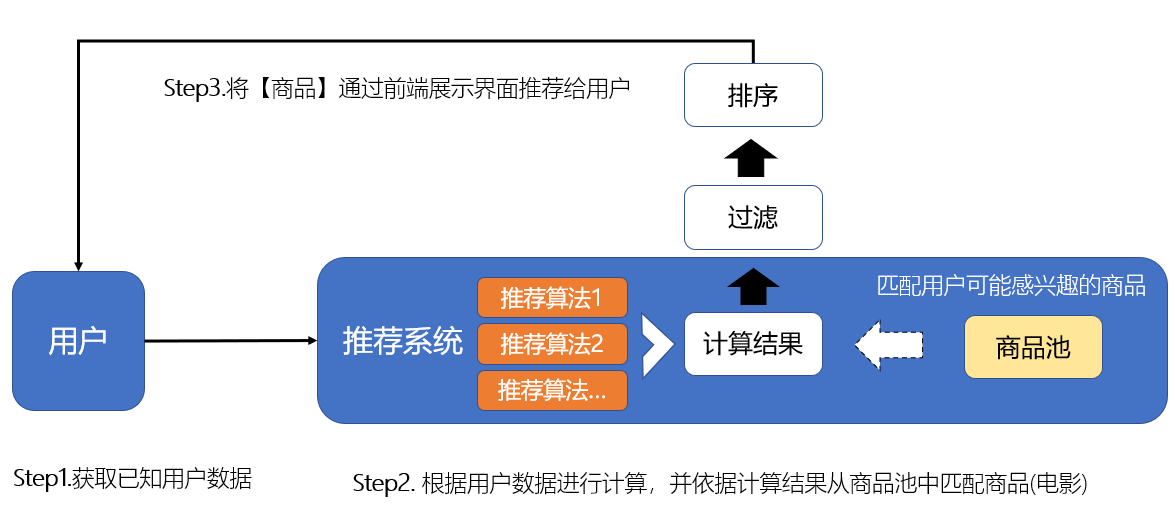
整个过程相对清晰,但总有点抽象。所以,我打算用一个简单的示例来进行回顾和说明。
延续上述提到的例子。我们统计了小明过去的观影数据,其中观看【喜剧片】10次、【悬疑片】5次、【战争片】4次、【爱情片】1次,那么加起来合计观影次数=10+5+4+1=20次,其中按照比例计算分别占比:50%、25%、20%、5%。
那么我们通过现有的数据可以观察到,该用户的仅有数据中显示其对【喜剧片】和【悬疑片】较为有兴趣(这里我们定义从历史数据中取Top2,【喜剧】和【悬疑】符合我们自定规则)。于是当小明下次开机时,来到了 页(这里示例默认了只使用一种推荐引擎)。此时系统的工作:
a. 从媒资库中取了 0部【喜剧片】和 0部【悬疑片】,并对两种类型的电影做了【过滤】,各剩下500部符合业务规则的电影。
b. 系统各将这500部电影按照【热度】进行了排序,原先的无序媒资集合有序了。
但是值得注意的是,这个集合很大,而我们现在 页的推荐位只有9个。我们需要解决的问题有两个,一个是我们已经知道的,我们1次 多只能推9个,另一个是我们要给小明推荐两种类型的影片,如何分配数量。
相信说到这里,大家自有答案。我们按照【喜剧片】50%占比,【悬疑片】25%占比:即【喜剧片】比【悬疑片】=2:1来分配数量。于是【喜剧片】=9*2/3=6个,【悬疑片】=9*1/3=3个。
c. 如此,我们将媒资集合中【喜剧片】排名前6个影片以及【悬疑片】前3个影片,呈现在小明的眼前。
以上大致是一个简要的推荐系统的构建以及整个过程的描述。
当然在实际的业务中,会有偏差,也有一部分重要的问题这里没有提及。比如:推荐算法种类的多样性和准确性;推荐结果的反馈、推荐效果如何等等。
总而言之,通过整个过程我们大致了解了推荐系统的本质,也了解到一个简要的推荐系统如何构建以及可能存在的问题和优化的方向。如果这个目的实现了,那么本文的目的也就达到了。希望对有需要的朋友提供思路,同时也欢迎多多交流。
四、心得:写在 后
推荐系统对于一个产品经理来说不是一个常见的产品,因为市面上几乎找不到类似的产品,更别说做什么竞品分析。因为能使用到推荐系统的公司往往都是科技巨头,比如电商平台淘宝京东PDD、短视频平台小破站抖音等或者其他的平台型公司,主要原因在于这些平台有大量的用户同时也有大量的信息/商品。
一般的公司是不可能用到这样的系统,自然市面上就没有较多的参考内容,所以整个系统可以看作是一个自主原创的从0到1。
总的来说,这个产品对我来说 大的价值在于:实现“知行合一”,即一次较为成功的自我认知和实践的闭环。


